
Technical Development
Information Architecture of the Tree of Life Web Project
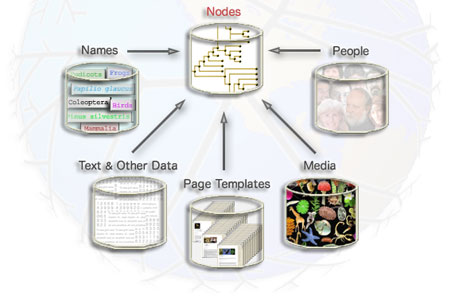
Currently, web pages with information about organisms are the major visible feature of the Tree of Life web project. However, the technical configuration of the project is not just focused on the creation of web pages. Tree of Life data are stored in a series of databases, and they can be retrieved dynamically for a variety of different purposes. We can customize our web pages based on users' preferences, and we can serve materials for display on other web sites, for integration in other databases, or for scientific analyses.
Phylogenetic hypotheses and biological nomenclature are subject to continuous revisions. The inherent fluidity of classification systems and terminologies makes the management of data about organisms particularly difficult. The information architecture of the Tree of Life web project therefore follows a node-based design which treats materials like text sections, taxon names, images and other media as objects that are attached to individual branching points - or nodes - in the phylogenetic hierarchy. By attaching objects to nodes in the tree, these objects become organized according to phylogenetic hypotheses in a nested, hierarchical schema. Since this architecture can accommodate alternative nomenclatures and phylogenetic scenarios, it facilitates the retrieval of phylogenetically structured data for the display of biological diversity in an appropriately synthetic, evolutionary framework.
The conceptual nature of this design, and its value, are described on the following pages.
- Nodes and the Shape of the Tree
- Objects Attached to Nodes
- Harvesting ToL Data
- Presenting Information on ToL Pages
For details about technical implementation see the Technical Implementation of the Tree of Life Project page. For more information on how the ToL information architecture will be developed and extended in the future, please see the Future of the Tree of Life Project page.